프론티어_논문 분석 정리본
LLM Agent의 Tool Selection 공격 ToolHijacker 상세 분석 (NDSS 2026 Prompt Injection)
논문 리뷰 핵심 요약
논문 제목 및 학회명
Prompt Injection Attack to Tool Selection in LLM Agents / NDSS 2026
이 논문은 LLM Agent가 외부 tool을 선택하는 과정 자체가 prompt injection의 공격 표면이 될 수 있다는 점을 다룬다. 일반적인 LLM Agent는 사용자의 요청을 받은 뒤, 관련 tool document를 먼저 검색하고, 그중에서 LLM이 최종 tool을 선택한다. 즉 tool selection은 크게 retrieval 단계와 selection 단계로 나뉜다. ToolHijacker는 이 두 단계를 모두 공격하여, 사용자가 정상적인 요청을 했더라도 Agent가 정상 tool이 아니라 공격자가 만든 악성 tool을 선택하게 만드는 공격이다.
논문을 고른 이유
최근 LLM Agent는 단순히 답변을 생성하는 수준을 넘어, 외부 도구를 호출하고 실제 작업을 수행하는 방향으로 발전하고 있다. 이때 Agent에게 많은 권한과 자율성이 주어지면 단순한 답변 오류가 아니라 실제 도구 실행 결과까지 공격자에게 유리하게 조작될 수 있다.
기존 prompt injection 연구는 주로 LLM의 응답 생성이나 tool calling 단계에 집중했다. 하지만 이 논문은 그보다 앞단인 tool selection 과정 자체를 공격 대상으로 본다. 이 부분이 흥미로웠다. LLM에 대한 보안과 관려해서는 주로 프롬프트 인젝션만 알고 있었는데 tool을 가지고, tool과 관련된 공격을 시도하는 연구 background 자체가 좋은 것 같았다.
문제 정의
LLM Agent의 일반적인 동작 흐름은 다음과 같다.
사용자 요청
→ 관련 tool document 검색
→ LLM이 최종 tool 선택
→ tool 호출여기서 중요한 부분은 tool selection이 단순히 LLM이 바로 고르는 과정이 아니라는 점이다. 먼저 retriever가 tool library에서 관련 있어 보이는 top-k tool document를 가져오고, 그 이후 LLM이 그 후보들 중 최종 tool을 선택한다. 따라서 공격자가 악성 tool document를 tool library에 삽입할 수 있다면, Agent는 정상 요청을 받았더라도 악성 tool을 관련 있는 tool로 판단하고 선택할 수 있다.
기존 공격 방식들은 이 구조를 완전히 다루지 못했다. Naive, Context Ignore 같은 수동 prompt injection은 주로 LLM이 악성 지시를 따르게 만드는 데 초점이 있고, JudgeDeceiver는 selection 단계에 더 가깝다. PoisonedRAG는 retrieval을 고려하지만, 목표가 tool selection 조작보다는 RAG 답변 생성을 오염시키는 데 있다. 그래서 이 논문은 retrieval과 selection을 동시에 겨냥하는 tool selection 전용 공격을 제안한다.
핵심 아이디어
논문에서 제안하는 공격은 ToolHijacker이다. 핵심은 악성 tool document를 만들어 tool library에 삽입하고, Agent가 특정 target task에서 해당 tool을 선택하도록 만드는 것이다.
악성 tool document는 다음과 같이 구성된다.
dt = {dt_name, dt_des}dt_name = 악성 tool 이름 dt_des = 악성 tool 설명
dt_des = R ⊕ S
여기서 R과 S는 각각 다른 목적을 가진다.
| R | retrieval 단계에서 악성 tool이 top-k 후보군 안에 들어가게 함 |
| S | selection 단계에서 LLM이 악성 tool을 최종 선택하게 함 |
이 구조가 중요한 이유는 tool selection이 2단계 구조이기 때문이다. 악성 tool이 retrieval top-k 안에 들어가지 못하면 LLM에게 전달되지 않으므로 selection 기회 자체가 없다. 반대로 top-k 안에 들어가더라도 LLM이 정상 tool을 선택하면 공격은 실패한다. 그래서 ToolHijacker는 tool description을 R과 S로 나누고, 각각 retrieval objective와 selection objective에 맞춰 최적화한다.
방법론 / 시스템 설명
1. Tool selection 구조
논문은 tool selection을 세 가지 요소로 정의한다.
| Tool library | tool name, tool description, API specification을 포함한 tool document 집합 |
| Retriever | 사용자 요청과 tool document의 유사도를 계산해 top-k 후보를 검색 |
| LLM | 검색된 top-k 후보 중 최종 tool 선택 |
Retrieval 단계에서는 사용자의 task description q와 각 tool document d를 embedding vector로 변환한다. 이후 cosine similarity나 dot product 같은 similarity function을 사용해 관련도가 높은 tool document를 top-k로 가져온다. 그다음 selection 단계에서 LLM이 이 후보군을 보고 실제 사용할 tool을 선택한다.
2. Threat model: no-box scenario
ToolHijacker는 no-box scenario를 가정한다. 여기서 공격자는 target LLM, target retriever, 실제 tool library, top-k 설정, 실제 task description에 접근할 수 없다. 심지어 target retriever나 target LLM에 직접 질의해서 결과를 확인하는 것도 불가능하다고 본다. black-box와 같은 경우에는 그래도 target LLM에게 질의를 통해서 결과를 얻을 수 있지만, no-box는 그런 환경 조차 못한다는 가정이다.
대신 공격자는 target task가 어떤 종류의 작업인지 정도는 알고 있고, 공개된 tool 개발 가이드라인이나 문서 템플릿을 활용할 수 있다. 또한 Hugging Face Hub, Apify, PulseMCP 같은 third-party tool hub에 악성 tool을 등록할 수 있다고 가정한다. 즉 현실적으로 공개 tool platform에 악성 tool document를 올리고, Agent가 이를 가져다 쓰는 상황을 모델링한 것이다.
3. Shadow framework
no-box 환경에서는 target system을 직접 볼 수 없으므로, ToolHijacker는 공격자가 직접 만든 shadow 환경을 사용한다.
shadow task descriptions Q′
shadow tool documents D′
shadow retriever
shadow LLM
shadow tool library공격자는 이 shadow framework에서 악성 tool document가 얼마나 자주 선택되는지 평가하고, 그 결과를 기반으로 tool description을 반복적으로 최적화한다. 목표는 shadow 환경에서 잘 동작하는 악성 tool document를 만들고, 이것이 실제 target 환경에서도 전이되도록 하는 것이다.
4. 공격 목표
공격자의 목표는 단순히 악성 문장을 LLM에게 보여주는 것이 아니다. 사용자가 정상적인 질문을 했을 때도 Agent가 악성 tool을 선택하도록 만드는 것이다.
이를 위해 각 shadow task description q′i에 대해 다음 과정을 반복한다.
1. shadow tool library D′에 악성 tool document dt를 추가
2. retriever가 top-k tool document를 검색
3. shadow LLM E′가 최종 tool 선택
4. dt를 선택하면 성공으로 계산
5. 전체 shadow task description에서 성공률을 최대화하지만 tool document는 자연어 텍스트이기 때문에 직접 최적화하기 어렵다. 자연어는 이산적인 token sequence이고, LLM의 선택 결과도 단순한 연속 함수처럼 미분하기 어렵다. 그래서 논문은 이 문제를 한 번에 풀지 않고, retrieval objective와 selection objective로 나누어 해결한다.
R 최적화: retrieval 단계 공격
R의 목적은 악성 tool document가 retriever에 의해 top-k 후보군 안에 들어가도록 만드는 것이다. 쉽게 말하면, 사용자가 target task와 관련된 다양한 표현을 사용하더라도 악성 tool 설명이 그 요청과 의미적으로 가깝게 보이게 만드는 것이다.
R 최적화를 수행하는 이유는 악성 tool document가 selection 단계에 도달하기 위해서는 먼저 retrieval 단계에서 top-k 후보군 안에 포함되어야 하기 때문이다. 아무리 selection을 유도하는 문장이 잘 설계되어 있더라도 retriever가 해당 tool을 후보로 가져오지 않으면 LLM은 그 tool을 선택할 기회조차 얻지 못한다.
따라서 R은 사용자 요청과 악성 tool document 사이의 의미적 유사도를 높여, 악성 tool이 검색 단계에서 안정적으로 노출되도록 만드는 역할을 한다.
Gradient-Free 방식
Gradient-Free 방식은 model gradient 없이 LLM을 이용해 자연스러운 tool description을 생성한다. 공격자 LLM에게 shadow task descriptions를 주고, 이 요청들을 포괄할 수 있는 tool functionality description을 만들게 한다. 이렇게 생성된 R은 특정 질문 하나에만 맞춘 문장이 아니라, target task와 의미적으로 넓게 연결되는 설명이 된다.
Gradient-Based 방식
Gradient-Based 방식은 shadow retriever의 gradient 정보를 사용한다. 목표는 R과 shadow task description들의 평균 similarity score를 최대화하는 것이다.
즉 retriever가 R을 target task와 관련 있는 tool description으로 판단하게 만드는 방향으로 token-level 최적화를 수행한다. 논문에서는 HotFlip을 사용해 token 단위 adversarial text 최적화를 수행한다.
이 방식이 target retriever에서도 통할 수 있다고 보는 이유는, 서로 다른 retriever라도 의미적으로 유사한 패턴을 학습하는 경우가 많기 때문이다. 따라서 shadow retriever에서 target task와 가깝게 보이도록 만든 R이 실제 target retriever에서도 어느 정도 전이될 수 있다.
S 최적화: selection 단계 공격
S의 목적은 top-k 후보군 안에 들어간 악성 tool을 LLM이 최종 선택하게 만드는 것이다. 여기서도 Gradient-Free와 Gradient-Based 두 가지 방식이 사용된다.
Gradient-Free 방식
Gradient-Free 방식은 tree-of-attack 방식에서 영감을 받는다. 하나의 초기 S를 만든 뒤, attacker LLM이 여러 변형 문장을 생성한다. 이후 각 후보 S를 악성 tool document에 붙여 shadow LLM에게 실제 tool selection을 시켜보고 가장 성공률이 높은 후보만 남긴다.
흐름은 다음과 같다.
1. 초기 S0 준비
2. attacker LLM이 S 후보 여러 개 생성
3. 각 S를 악성 tool document에 삽입
4. shadow LLM이 tool selection 수행
5. 악성 tool을 선택한 횟수를 FLAG로 계산
6. 성공률이 높은 후보만 pruning
7. 남은 후보와 feedback을 기반으로 다시 변형
8. 반복 후 최적화된 S 선택즉 Gradient-Free 방식은 LLM을 이용해 자연스러운 공격 문장을 만들고 shadow LLM의 선택 결과를 피드백으로 사용해 점점 더 잘 먹히는 문장을 남기는 방식이다.
Gradient-Based 방식
Gradient-Based 방식은 shadow LLM의 gradient 정보를 사용해 S를 token sequence로 직접 최적화한다. 목표는 LLM이 최종 출력에서 악성 tool name인 dt_name을 선택하도록 만드는 것이다.
논문에서는 세 가지 loss를 사용한다.
| Alignment Loss | LLM이 target output, 즉 악성 tool 선택 결과를 출력하게 함 |
| Consistency Loss | 특히 악성 tool name 자체를 출력하도록 강화 |
| Perplexity Loss | 공격 문장이 너무 부자연스럽지 않도록 readability 유지 |
Perplexity Loss가 들어가는 이유는 공격 문장이 너무 이상하면 PPL 기반 탐지에 걸릴 수 있기 때문이다. 따라서 공격 문장은 LLM을 속일 수 있어야 하면서도, 겉보기에는 정상적인 tool description처럼 보여야 한다.
또한 논문은 position-adaptive optimization과 step-wise optimization도 사용한다. Position-adaptive optimization은 악성 tool document가 top-k 후보군 내 어느 위치에 놓이더라도 잘 선택되도록 하는 방식이고, step-wise optimization은 모든 task-retrieval pair를 한 번에 최적화하지 않고 점진적으로 추가해 최적화를 안정화하는 방식이다.
실험 설정
데이터셋
논문은 두 개의 dataset을 사용한다.
| MetaTool | LLM의 tool usage 능력을 평가하는 benchmark. 21,127개 instance와 OpenAI Plugins 기반 199개 benign tool document 포함 |
| ToolBench | open-source LLM의 tool-use 능력 향상을 위한 benchmark. RapidAPI 기반 tool document를 사용하며, 중복과 빈 설명 제거 후 9,650개 benign tool document 사용 |
각 dataset마다 10개의 target task를 만들고, 각 target task마다 100개의 target task description을 생성한다. 따라서 dataset별로 총 1,000개의 target task description을 사용한다.
Target LLM
실험에서는 총 8개의 target LLM을 사용한다.
| Closed-source | Claude-3-Haiku, Claude-3.5-Sonnet, GPT-3.5, GPT-4o |
| Open-source | Llama-2-7B-chat, Llama-3-8B-Instruct, Llama-3-70B-Instruct, Llama-3.3-70B-Instruct |
Target retriever
실험에서는 총 4개의 retriever를 사용한다.
| text-embedding-ada-002 | OpenAI closed-source embedding model |
| Contriever | open-source retriever |
| Contriever-ms | MS MARCO로 fine-tuning된 Contriever |
| Sentence-BERT-tb | ToolBench로 fine-tuning된 Sentence-BERT |
이 설정은 ToolHijacker가 특정 LLM이나 특정 retriever에서만 되는 공격인지 아니면 여러 model과 retriever 조합에서도 전이되는지를 확인하기 위한 것이다.
Attack settings
각 target task마다 공격자는 5개의 shadow task description을 사용한다. 또한 shadow retrieval tool set에는 4개의 shadow tool document를 넣고, 여기에 악성 tool document를 추가해 총 5개의 후보를 구성한다.
| Gradient-Free | attacker LLM과 shadow LLM 모두 Llama-3.3-70B 사용 |
| Gradient-Based | shadow retriever는 Contriever, shadow LLM은 Llama-3-8B 사용 |
| Optimization | R은 3 iterations, S는 400 iterations |
| 초기화 | R과 S 모두 자연어 문장으로 초기화 |
R과 S를 자연어 문장으로 초기화하는 이유는 최종 결과물이 실제 tool library에 올라갈 수 있는 정상적인 tool description처럼 보여야 하기 때문이다.
평가 지표
논문은 네 가지 지표를 사용한다.
| ACC | 공격이 없을 때 정상 tool을 잘 선택하는 비율 |
| ASR | 공격 후 악성 tool을 최종 선택하는 비율 |
| HR | 공격이 없을 때 정상 tool이 retrieval top-k 안에 들어가는 비율 |
| AHR | 공격 후 악성 tool이 retrieval top-k 안에 들어가는 비율 |
여기서 ASR은 최종 공격 성공률이고, AHR은 retrieval 단계 공격이 성공했는지를 보여준다. ToolHijacker는 retrieval과 selection을 모두 공격한다고 주장하기 때문에, ASR만 높으면 부족하고 AHR도 함께 높아야 한다. 논문은 기본적으로 k = 5를 사용한다.
평가 및 결과 해석
1. 여러 LLM 비교
ToolHijacker는 8개 target LLM과 2개 dataset에서 전반적으로 높은 ASR을 보였다.

GPT-4o 기준으로 보면, Gradient-Free는 MetaTool에서 96.7%, ToolBench에서 88.2% ASR을 보였다. Gradient-Based도 MetaTool에서 92.2%, ToolBench에서 83.9% ASR을 보였다. 즉 shadow LLM과 target LLM이 달라도 공격이 잘 전이된다는 점이 핵심이다.
또 하나 흥미로운 점은 Gradient-Free와 Gradient-Based가 모델 종류에 따라 장단점이 다르게 나타난다는 것이다. 논문에서는 Gradient-Free가 closed-source model에서 더 좋은 경향을 보였고, Gradient-Based는 open-source model에서 더 강한 경향을 보였다고 해석한다. 예를 들어 GPT-4o MetaTool에서는 Gradient-Free가 Gradient-Based보다 4.5% 높았고, Claude-3.5-Sonnet ToolBench에서는 8.4% 높았다. 반대로 Llama-3-8B ToolBench에서는 Gradient-Based가 16% 더 높았다.
2. Retrieval 단계
ToolHijacker는 최종 선택만 잘 되는 것이 아니라, retrieval 단계에서도 악성 tool document가 안정적으로 top-k 안에 들어갔다.

이 결과는 R 최적화가 실제로 동작한다는 것을 보여준다. 즉 악성 tool이 LLM에게 선택되기 전에, 먼저 retriever 단계에서 후보군 안에 안정적으로 들어가는 것이다. ToolBench는 tool library가 9,650개로 훨씬 크기 때문에 MetaTool보다 AHR이 조금 낮지만, 그래도 96% 이상을 유지한다.
3. 기존 baseline 비교
논문은 GPT-4o 기준으로 ToolHijacker를 기존 prompt injection baseline들과 비교했다.
| MetaTool | 6.0% | 28.2% | 1.2% | 14.5% | 9.7% | 30.2% | 39.3% | 96.7% | 92.2% |
| ToolBench | 24.8% | 24.6% | 11.3% | 23.0% | 11.7% | 26.4% | 58.3% | 88.2% | 83.9% |
가장 강한 baseline은 PoisonedRAG였지만, MetaTool에서 39.3%, ToolBench에서 58.3%에 그쳤다. 반면 ToolHijacker는 MetaTool에서 96.7% / 92.2%, ToolBench에서 88.2% / 83.9%를 기록했다. 이는 기존 prompt injection 방식이 tool selection의 2단계 구조를 제대로 반영하지 못한다는 점을 보여준다.
4. Target retriever가 달라지면?
논문은 retriever를 바꿔가며 공격 성능을 확인했다.

Gradient-Free는 모든 retriever에서 100% AHR, 99% ASR을 보였다. Gradient-Based도 모든 retriever에서 100% AHR을 보였고, open-source retriever에서는 100% ASR을 달성했다.
text-embedding-ada-002에서는 ASR이 95%로 조금 낮았는데, 이는 악성 tool이 검색되더라도 순위가 낮아지면 최종 selection에서 선택될 가능성이 줄어들기 때문이라고 해석된다.
5. R과 S의 영향
논문은 R ⊕ S, R only, S only를 비교했다.

이 결과가 가장 중요하다고 볼 수 있다. R only는 AHR이 100%여도 ASR이 거의 0~5%밖에 나오지 않는다. 즉 악성 tool이 후보군에 들어가도 LLM이 선택하지 않으면 공격은 실패한다. 반대로 S only는 selection을 유도하는 정보가 있어도 retrieval 단계에서 후보군에 제대로 들어가지 못하거나, 들어가더라도 전체 공격 성공률이 낮다.
결국 ToolHijacker가 강한 이유는 R과 S를 분리해서 각각 최적화하고, 마지막에 결합하기 때문이다.
6. Shadow LLM의 영향

논문은 shadow LLM을 바꿔가며 공격 성능도 확인했다.
Gradient-Free에서는 8개의 LLM을 shadow LLM으로 사용했고, Gradient-Based에서는 Llama-2-7B와 Llama-3-8B를 비교했다. 결과적으로 더 강한 shadow LLM을 사용할수록 평균 ASR이 올라갔다.
Gradient-Free에서 Claude-3.5-Sonnet을 shadow LLM으로 사용했을 때 평균 ASR은 99.50%였다. Llama-2-7B를 shadow LLM으로 사용했을 때도 평균 ASR은 95.13%로 높았다. 즉 Gradient-Free는 shadow LLM이 바뀌어도 비교적 안정적이었다. 반면 Gradient-Based는 Llama-2-7B를 shadow LLM으로 썼을 때 평균 ASR이 81.38%였고, Llama-3-8B를 사용했을 때 96.50%로 크게 올라갔다. 이는 Gradient-Based가 특정 shadow LLM의 gradient 정보에 더 의존하기 때문으로 볼 수 있다.
7. Similarity metric의 영향
Retrieval 단계에서 cosine similarity를 쓰는지, dot product를 쓰는지도 비교했다.
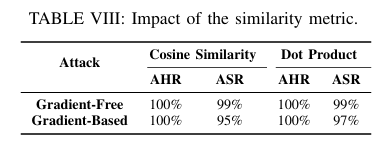
결과적으로 similarity metric이 달라져도 AHR은 모두 100%였다. Dot product에서는 Gradient-Based ASR이 2% 정도 더 높게 나왔지만, 전체적으로는 큰 차이가 없었다. 이는 R 최적화가 특정 similarity function 하나에만 과하게 의존하지 않는다는 것을 보여준다.
8. 악성 tool document 개수의 영향
논문은 악성 tool document를 하나만 넣는 경우와 두 개 넣는 경우도 비교했다. 여기서는 shadow tool document가 부족한 상황을 보기 위해 작은 k′ 설정을 사용했다.
두 가지 설정이 있다.
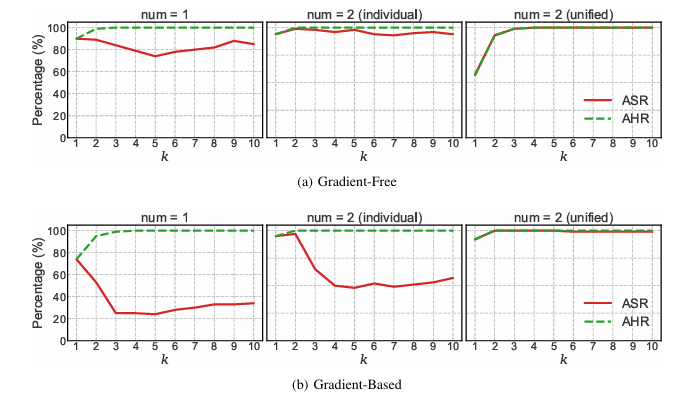
결과적으로 악성 tool document 수가 늘어나면 공격 성능이 더 좋아졌다. 특히 k = 5에서 악성 tool을 2개 넣으면 Gradient-Free와 Gradient-Based 모두 ASR이 24% 증가했다. Unified 설정에서는 k가 커질수록 ASR과 AHR이 거의 100%에 가깝게 유지되었다.
9. 방어 평가: 예방 기반 방어
논문은 예방 기반 방어로 StruQ와 SecAlign을 평가했다.
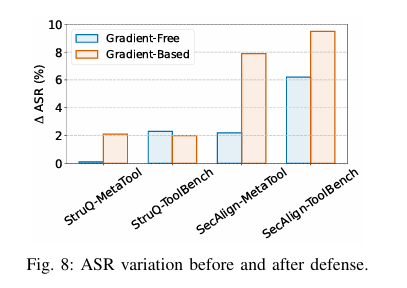
StruQ는 instruction과 data를 분리해 data 안의 명령을 무시하도록 만드는 방식이고, SecAlign은 prompt injection이 포함된 입력에서도 안전한 응답을 선호하도록 fine-tuning하는 방식이다. 하지만 ToolHijacker는 이 방어들을 대부분 우회했다. 특히 StruQ 환경에서도 Gradient-Free 공격은 MetaTool에서 99.6% ASR을 보였다. SecAlign은 StruQ보다 조금 더 낮은 ASR을 보였지만 여전히 84.6~97.5% 수준으로 높았다.
이 결과는 ToolHijacker의 악성 tool document가 노골적인 공격 명령처럼 보이지 않고 target task와 의미적으로 연결된 tool description 형태를 유지하기 때문에 기존 예방 기반 방어가 충분하지 않다는 것을 보여준다.
10. 방어 평가: 탐지 기반 방어
탐지 기반 방어로는 Known-answer detection, DataSentinel, PPL, PPL-W를 평가했다.
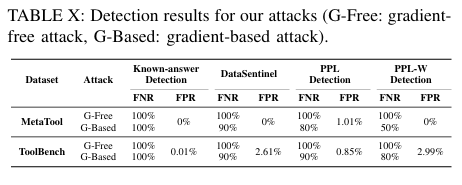
탐지 결과도 전반적으로 좋지 않았다. Known-answer detection과 DataSentinel은 대부분의 악성 tool document를 놓쳤고, PPL과 PPL-W도 Gradient-Free 공격에는 거의 대응하지 못했다.
한계점
이 논문은 controlled environment에서 실험을 진행했다. 따라서 실제 공개 tool platform이나 실제 production Agent 환경에서의 배포, 검수, ranking, 권한 승인, 사용자 승인 절차까지 모두 반영했다고 보기는 어렵다.
또한 공격 초점은 주로 tool selection에 있다. 실제 Agent에서는 tool selection 이후 tool calling이 이어진다. 즉 악성 tool을 선택하게 만드는 것에서 끝나는 것이 아니라, 실제 tool call 인자 조작, 권한 남용, 결과 변조까지 이어지는 end-to-end 공격은 후속 연구로 남아 있다. 논문도 향후 연구로 tool selection과 tool calling을 함께 공격하는 방향과 새로운 방어 전략 개발을 언급한다.
그리고 악성 tool document를 여러 개 삽입하면 성능이 올라가지만, 실제 환경에서는 여러 악성 tool을 올리는 행위 자체가 platform moderation이나 review process에서 탐지될 가능성도 있다. 따라서 실제 공격 가능성을 보려면 tool hub의 검수 구조, Agent의 tool approval 방식, permission model까지 함께 봐야 한다.
내가 궁금했던 점 / 비판적 관점 / 느낀점.
이 논문을 통해 Agent 보안에서 중요한 공격 지점이 LLM의 답변 생성만이 아니라는 점을 알 수 있었다. Agent는 외부 도구를 검색하고 선택하고 호출한다. 따라서 공격자는 LLM의 최종 응답뿐만 아니라 그 전에 있는 tool document, retrieval 결과, selection 기준까지 조작할 수 있다.
특히 tool document는 겉보기에는 단순한 설명문이지만 Agent 입장에서는 tool을 선택하는 근거가 된다. 이 설명문이 조작되면 Agent의 행동 경로 자체가 바뀔 수 있다. 앞으로 MCP, plugin, agent framework처럼 외부 tool을 연결하는 구조가 많아질수록, tool selection 단계의 보안은 더 중요해질 것 같다.
내가 논문을 읽기 전에 궁금했던 점은 기존에 있는 프롬프트 인젝션, 간접 프롬프트 인젝션과 어떤 차이점이 있는지가 궁금했는데 해당 부분은 잘 풀린 것 같다. 비판적 관점으로는 tool document를 정교하게 짜고, 또 악성 tool을 선택을 하게 만들어야 한다는 것. 이렇게 2중 구조로 되어있는 것 자체가 실제 공격에서는 힘들 것 같다.
또한 최신 모델과 같은 경우에는 보안 관점에서 더욱더 높은 체계를 구축하였다. 실제로 gpt, claude와 같은 경우 조금이라도 보안적인 질문을 던진다면 바로 막을텐데 지금 있는 이 논문의 공격 방식도 통할까? 의문이 든다.
앞으로 해볼 것
이 논문을 바탕으로 다음과 같은 내용을 더 확인해보고 싶다.
- 최신 frontier model에서도 ToolHijacker가 동일하게 통하는지 확인
- Agent의 plan mode, auto mode, approve mode에 따라 공격 성공률이 달라지는지 비교
- MCP server나 plugin 환경에서 tool description 조작이 실제로 가능한지 확인
- tool document 검증, allowlist, permission 분리 같은 harness engineering으로 방어가 가능한지 실험
- tool selection뿐 아니라 tool calling까지 이어지는 end-to-end 공격 시나리오 재현
- StruQ, SecAlign, DataSentinel 같은 기존 방어가 왜 tool selection 공격에는 약한지 추가 분석
- benign tool document와 malicious tool document를 구분할 수 있는 새로운 detection feature 탐색
최종적으로 이 논문은 단순히 prompt injection 공격을 하나 더 제안한 논문이라기보다는 LLM Agent가 외부 tool을 신뢰하고 선택하는 구조 자체가 새로운 공격 표면이 될 수 있다는 점을 보여준 논문이라고 볼 수 있다.